HDFS概述及其优缺点
Hadoop分布式文件系统(Hadoop Distributed File System)基于GFS(Google File System)论文实现。
Apache Hadoop核心子项目之一,另两个是YARN和MapReduce。
在开源大数据技术体系中的地位,无可替代。
优点
- 海量存储(典型大小GB-TB,百万以上文件数量,PB以上数据规模)
- 高容错(多副本策略)、高可用(HA、安全模式)、高扩展(10K节点规模)
- 构建成本低(廉价商用机)、安全可靠(提供容错机制)
- 适合大规模离线批处理(流式数据访问、数据位置暴露给计算框架)
缺点
- 不适合低延迟数据访问
- 不适合大量小文件存储(会有很多元数据占用大量空间,移动计算时任务数量会很多)
- 不支持并发写入
- 不支持文件随机修改(仅支持追加写入)
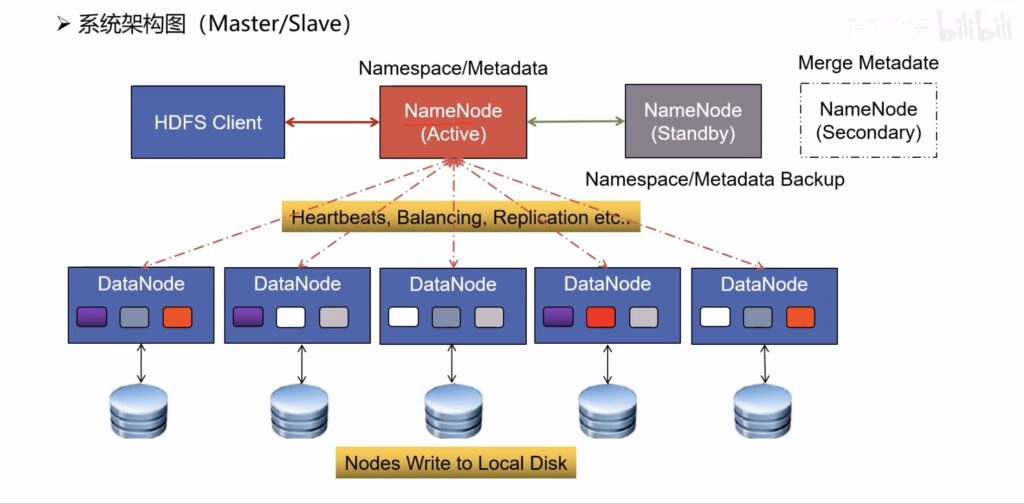
HDFS系统架构
文件视角下的Hadoop架构:
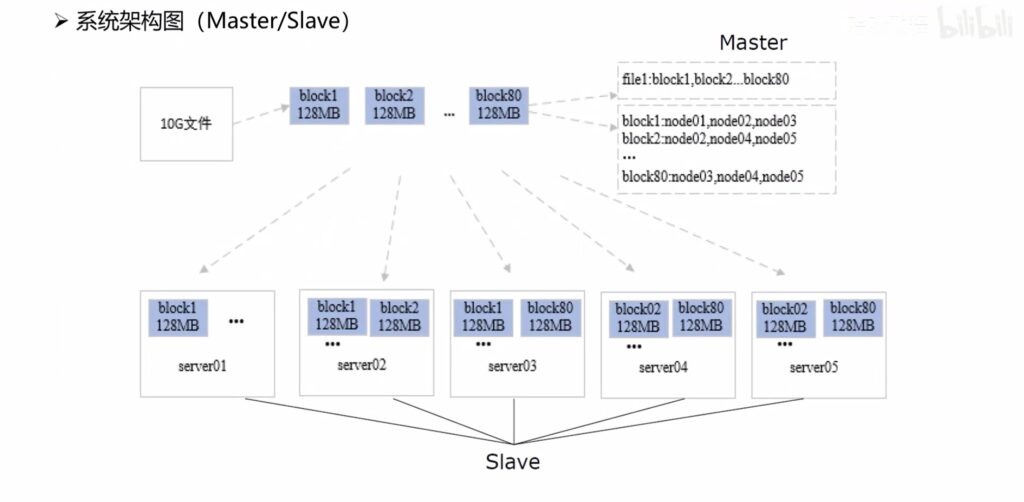
NameNode信息有两部分:切分的名称属性,多少块(重要);存在哪些DataNode中的信息不是很重要且更新频繁,因此不会持久化到文件中。
Block存储机制
- 默认大小128M,根据系统开销决定比如磁盘读写效率,和其他系统的对接。
- 多副本,存在DataNode中,自动创建。
- 存放策略:
- 副本1:优先找网络位置最近的
- 副本2:放在不同的机架节点上
- 副本3:放在与第二个副本不同的机架节点上
- 副本N:随机
- 节点选择:同等条件下选择空闲节点
元数据(Metadata)
存放在NameNode中
包含HDFS中文件及目录的基本属性信息(如拥有者、权限信息创建时间等)、文件有哪些block构成、以及block的位置存放信息。
元数据信息持久化
fsimage(元数据镜像检查点文件)
edits(编辑日志文件)
注:block的位置信息并不会做持久化,在DataNode启动或通过心跳汇报给NameNode。
edits与fsimage的合并机制
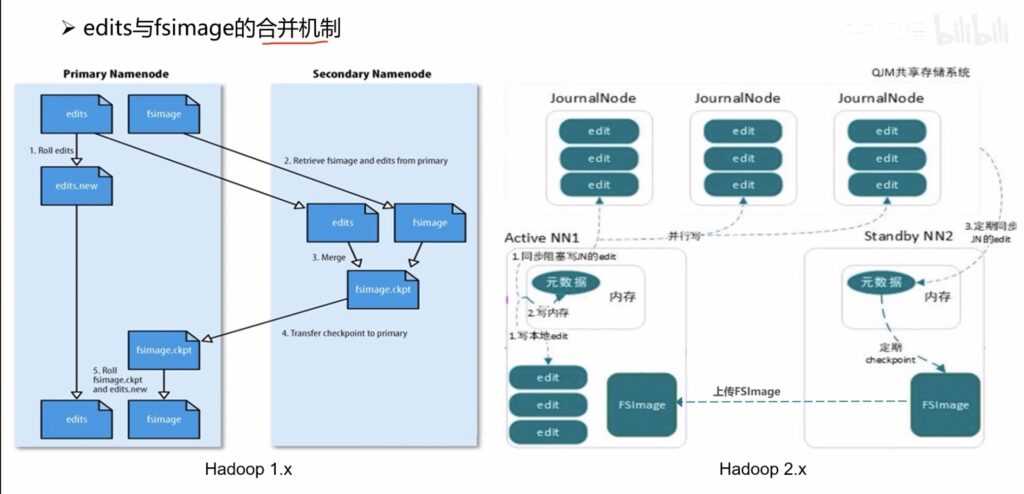
元数据信息持久化在NameNode中的存储结构
- fsimage文件是文件系统的元数据的持久性检查点,文件名上会记录对应的transactionID
- 文件系统客户端执行写操作的时候,首先会先记录在edit log中,通过前后缀记录当前操作的transactionID:记录后则认为是一次成功的操作
注:in_use.lock 文件表示NameNode正在对文件夹进行操作
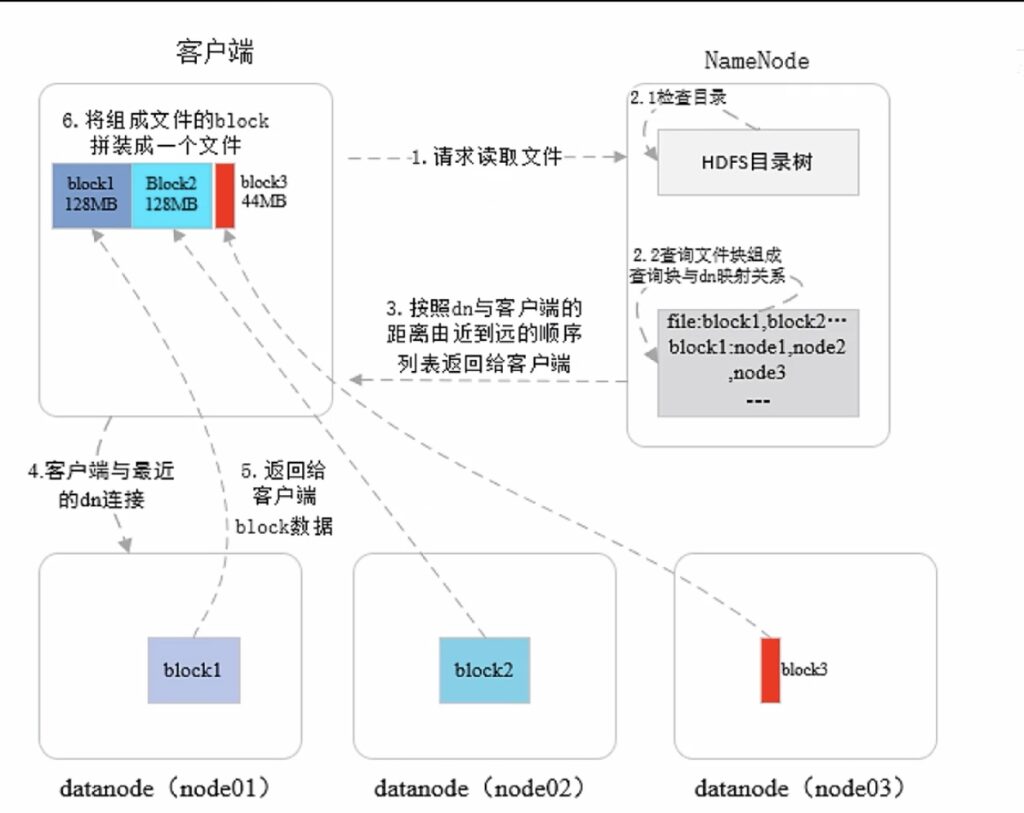
HDFS读写操作
写操作
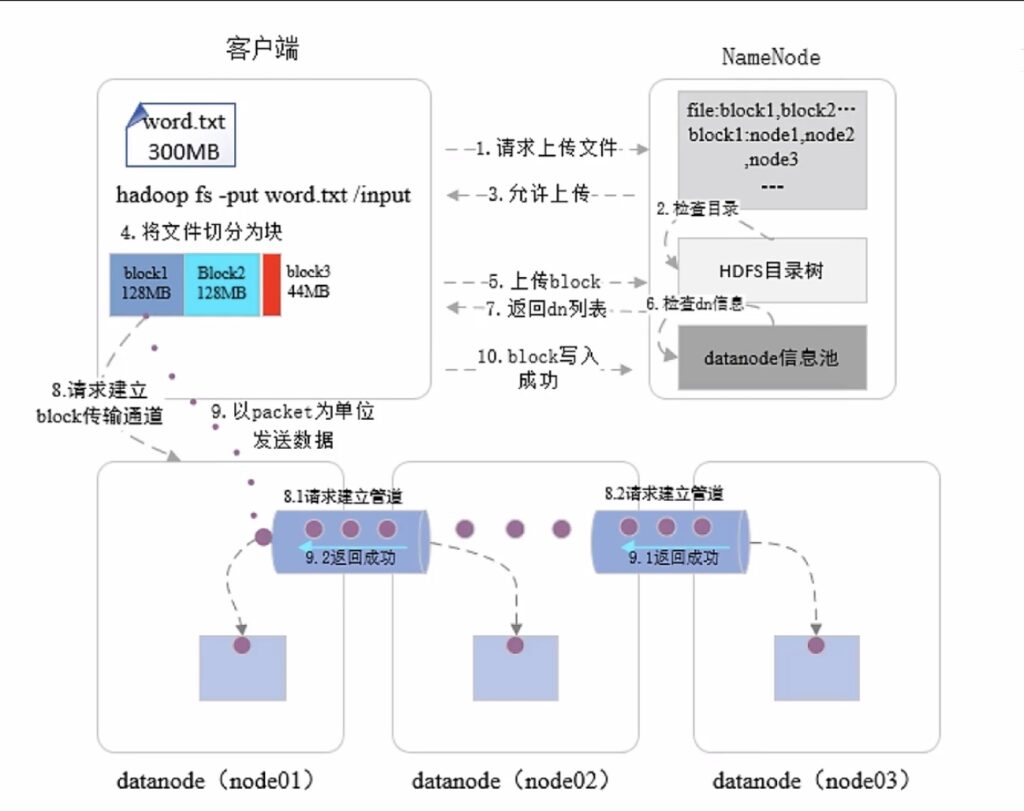
读操作
HDFS单节点架构存在的问题
- 内存受限,单机内存始终有限,不能满足多个datanode的使用
- 单节点故障,会导致直接不可用
NameNode的高可用机制
在2.x版本中提出,至少两台NameNode进行热备:Active、Stanby;一台宕机,另一台保持元数据一致,并进行状态转换;QJM和NFS机制是NameNode高可用的两种实现。

使用QJM实现元数据edits文件高可用
用Journal集群存储edits编辑日志,奇数台(2N+1);半数返回成功就表示写入成功;最多可容忍N个Journal主机宕机;基于Paxos算法实现。

